Now - while we’ve primarly worked in Python throughout, sometimes we come across an R package that suits our needs better than the Python equivalent. While the excellent pm4py process mining package exists too, bupaR’s visuals are top notch.
There are a few different ways we could get our Python event logs to work with bupaR:
the reticulate package (which runs Python from R) - though due to the complexity of our code, this is likely to run into issues
the r2py package (which runs R from Python) - as we only want a little bit of R in a primarily Python project, this might be a better option
Quarto’s features for passings objects like dataframes between R and Python cells
exporting our event log as a csv, importing this into R, and saving the resulting bupaR visuals
the visuals we export can then be imported back into Streamlit apps or Quarto reports
we could take this even further by using a column-type preserving data format that is interoperable between R and Python, like Feather or Parquet.
In this chapter, we will use option 4.
The first thing we are going to do is add some extra bits that bupar requires.
import pandas as pdevent_log = pd.read_csv("resources/sample_event_log_10_day_10_run.csv")df = event_log[(event_log["event_type"]=="queue") | (event_log["event_type"]=="resource_use")].copy()df["activity_id"] = df.groupby("run").cumcount() +1# Duplicate rows and modify themdf_start = df.copy()df_start["lifecycle_id"] ="start"df_end = df.copy()df_end["lifecycle_id"] ="complete"# Shift timestamps for 'end' rowsdf_end["time"] = df_end["time"].shift(-1)# Combine and sortdf_combined = pd.concat([df_start, df_end]).sort_index(kind="stable")# Drop last 'end' row (since there’s no next row to get a timestamp from)df_combined = df_combined[:-1]df_combined.to_csv("resources/bupar_log.csv", index=False)df_combined.head(30)
Rows: 86059 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): pathway, event_type, event, lifecycle_id
dbl (5): entity_id, time, resource_id, run, activity_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `timestamp_dt = (function (..., quiet = FALSE, tz = "UTC",
locale = Sys.getlocale("LC_TIME"), ...`.
Caused by warning:
! 4 failed to parse.
## !!!! Note that the bupaR documentation recommmends using the## to_activitylog() function at the end of this set of steps.## This caused significant errors in testing of this codehead(activity_log, 20)
Warning in process_map.eventlog(., frequency("absolute")): Some of the
timestamps in the supplied event log are missing (NA values). This may result
in a invalid process map!
Warning in process_map.eventlog(., frequency("absolute-case")): Some of the
timestamps in the supplied event log are missing (NA values). This may result
in a invalid process map!
Warning in process_map.eventlog(., frequency("relative")): Some of the
timestamps in the supplied event log are missing (NA values). This may result
in a invalid process map!
31.1.1.2 Performance maps
31.1.1.2.1 Mean Times
activity_log %>%process_map(performance())
Warning in process_map.eventlog(., performance()): Some of the timestamps in
the supplied event log are missing (NA values). This may result in a invalid
process map!
Warning in process_map.eventlog(., performance(FUN = max)): Some of the
timestamps in the supplied event log are missing (NA values). This may result
in a invalid process map!
Warning: There was 1 warning in `summarize()`.
ℹ In argument: `label = do.call(...)`.
ℹ In group 5: `ACTIVITY_CLASSIFIER_ = NA` and `from_id = NA`.
Caused by warning in `type()`:
! no non-missing arguments to max; returning -Inf
Warning: There were 2 warnings in `summarize()`.
The first warning was:
ℹ In argument: `value = do.call(...)`.
ℹ In group 1: `ACTIVITY_CLASSIFIER_ = "ARTIFICIAL_END"`, `next_act = NA`,
`from_id = 1`, `to_id = NA`.
Caused by warning in `type()`:
! no non-missing arguments to max; returning -Inf
ℹ Run `dplyr::last_dplyr_warnings()` to see the 1 remaining warning.
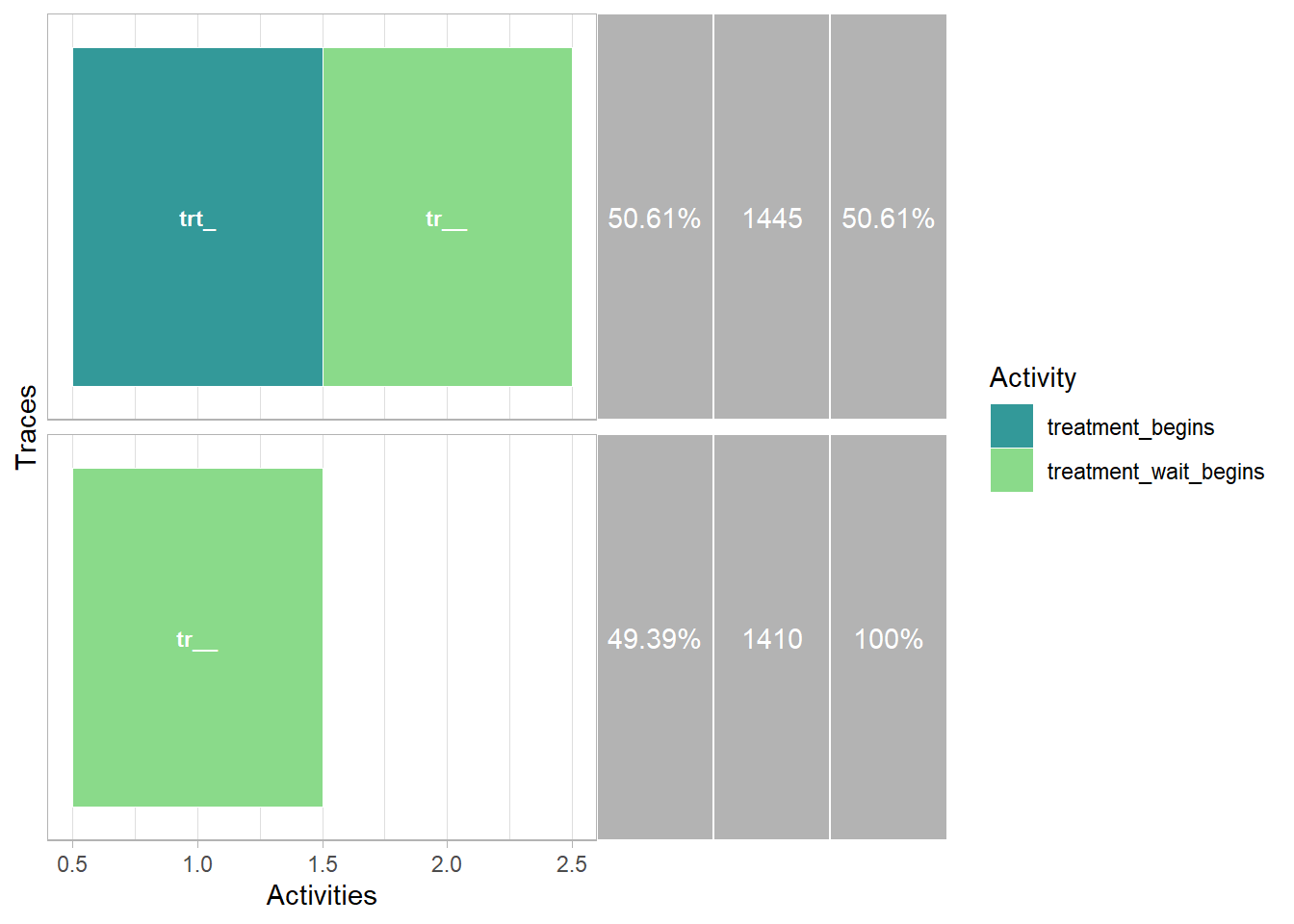
31.1.1.3 Common Routes
activity_log %>%trace_explorer(n_traces =10)
Warning: Fewer traces (2) found than specified `n_traces` (10).
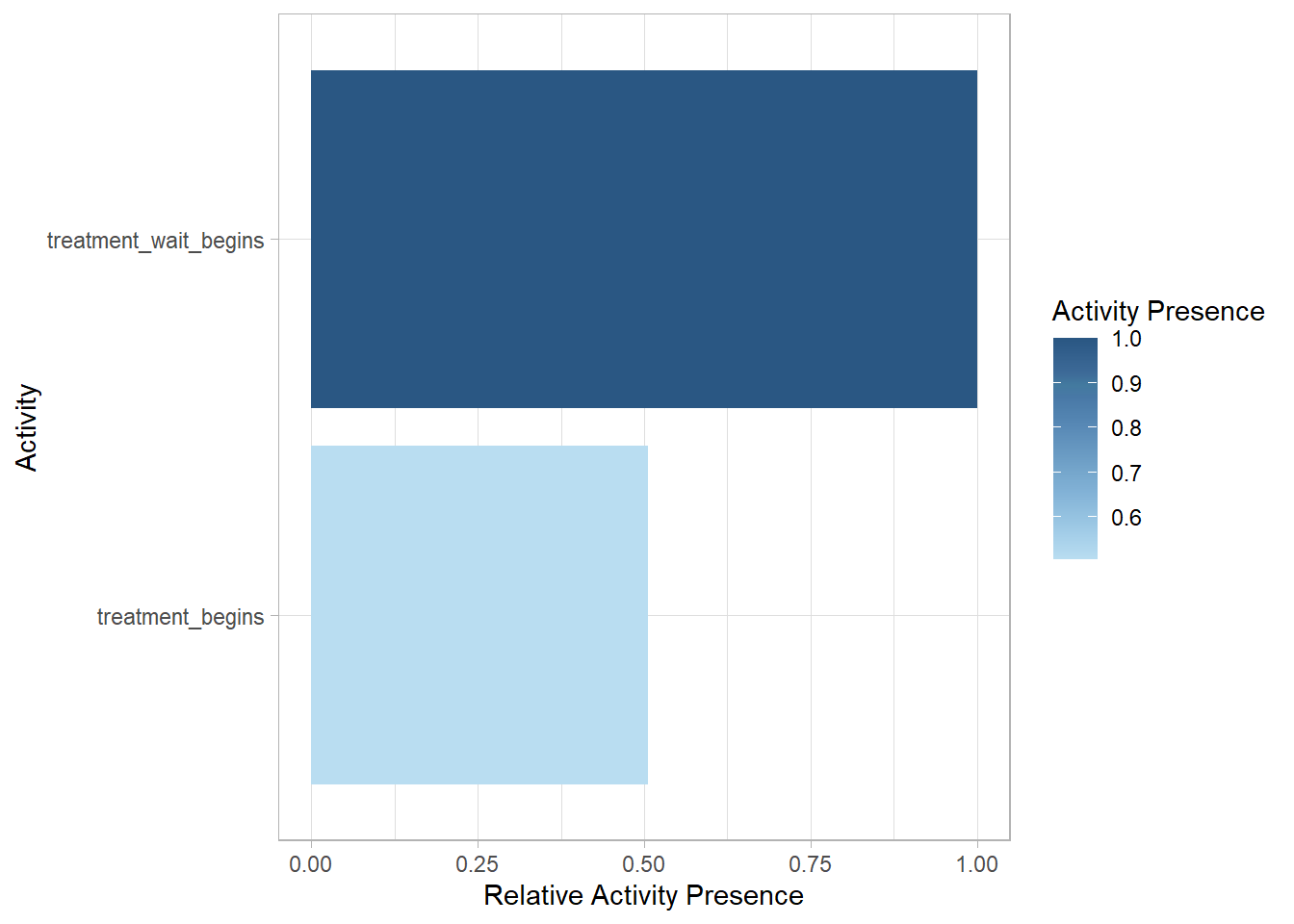
31.1.1.4 Activity Presence
activity_log %>%activity_presence() %>%plot()
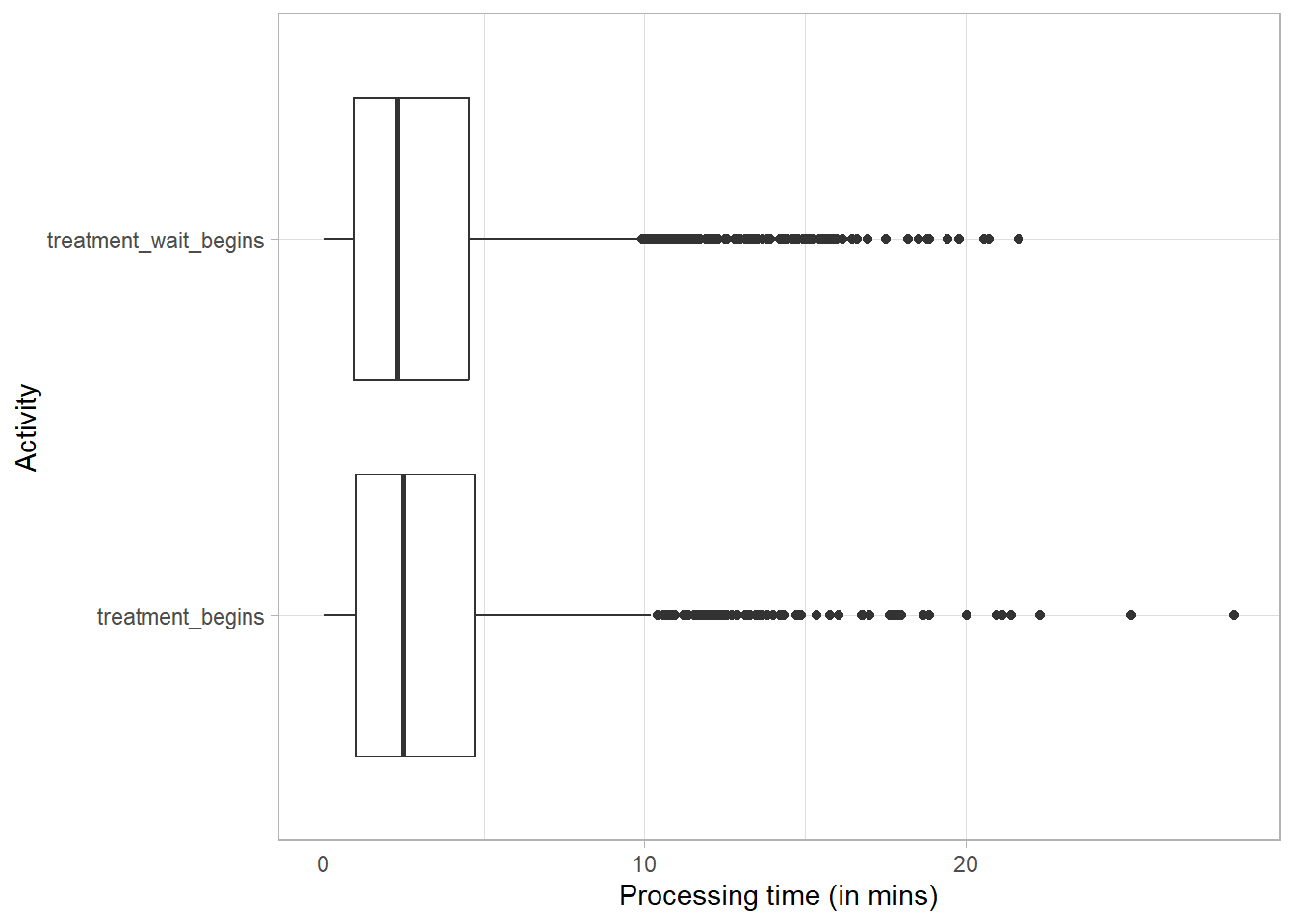
31.1.1.5 Processing Time
activity_log %>%processing_time("resource-activity", units ="mins") %>%plot()
Warning: The following aesthetics were dropped during statistical transformation: colour
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
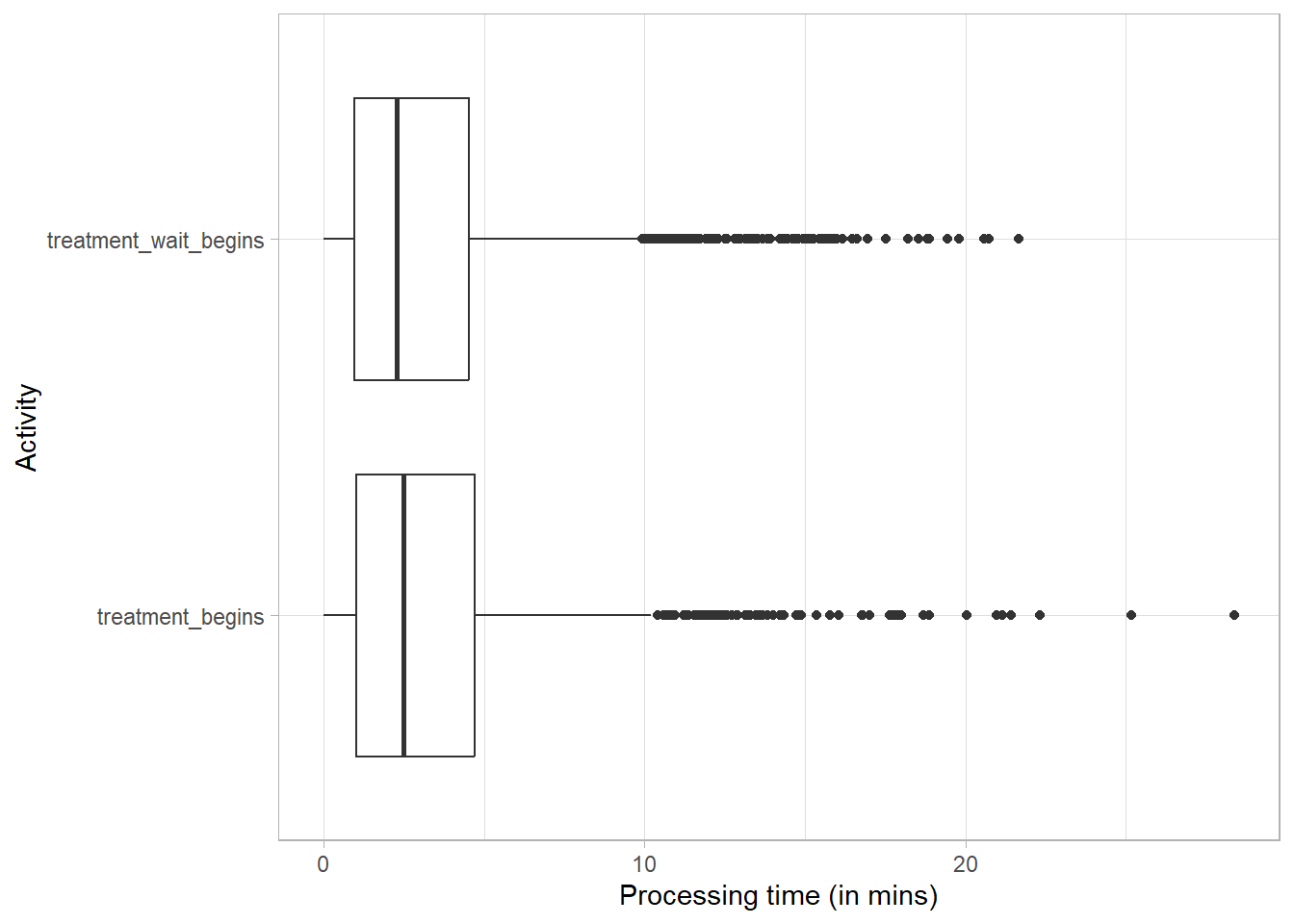
activity_log %>%processing_time("activity", units ="mins") %>%plot()
activity_log %>%idle_time("resource", units ="mins") %>%plot()
31.1.2 bupaR Animated Outputs
activity_log %>%animate_process()
Warning in process_map.eventlog(eventlog, render = F, ...): Some of the
timestamps in the supplied event log are missing (NA values). This may result
in a invalid process map!
31.2 Working with a more advanced simulation log
31.2.1 Generating a flexible python function for moving from event logs to process logs
Let’s turn our code for processing our event log into its own reusable function.
To help our visualisations distinguish between different resources better, we’ll also adjust the resource IDs to reflect which process they are being used with.
def process_event_log_for_bupar(event_log_path): event_log = pd.read_csv(event_log_path) df = event_log[(event_log["event_type"]=="queue") | (event_log["event_type"]=="resource_use")].copy() df["activity_id"] = df.groupby("run").cumcount() +1# Duplicate rows and modify them df_start = df.copy() df_start["lifecycle_id"] ="start" df_end = df.copy() df_end["lifecycle_id"] ="complete"# Shift timestamps for 'end' rows df_end["time"] = df_end["time"].shift(-1)# Combine and sort df_combined = pd.concat([df_start, df_end]).sort_index(kind="stable")# Drop last 'end' row (since there’s no next row to get a timestamp from) df_combined = df_combined[:-1] df_combined["resource_id"] = df_combined.apply(lambda x: f"{x['event']}_{x['resource_id']:.0f}", axis=1) df_combined.to_csv(f"{event_log_path.replace('.csv', '')}_bupar_log.csv", index=False)return df_combinedbupar_log_complex = process_event_log_for_bupar("resources/complex_event_log.csv")bupar_log_complex.head(30)
The following object is masked from 'package:edeaR':
trace_length
library(glue)create_activity_log <-function(filepath,run_id =1,simulation_start =ymd_hms("2025-01-01 00:00:00"),case_id ="entity_id",activity_id ="event",activity_instance_id ="activity_id",lifecycle_id ="lifecycle_id",resource_id ="resource_id",time_column ="time",run_column ="run") {# Read the data data <- readr::read_csv(filepath)# Validate that all required columns exist required_cols <-c(case_id, activity_id, activity_instance_id, lifecycle_id, resource_id, time_column, run_column) missing_cols <-setdiff(required_cols, names(data))if (length(missing_cols) >0) {stop(glue::glue("Missing required columns: {paste(missing_cols, collapse=', ')}")) }# Tidy evaluation symbols time_col_sym <- rlang::sym(time_column) run_col_sym <- rlang::sym(run_column)# Validate that the requested run_id exists available_runs <-unique(dplyr::pull(data, !!run_col_sym))if (!run_id %in% available_runs) {stop(glue::glue("Run ID {run_id} not found. Available run IDs: {paste(available_runs, collapse=', ')}")) }# Filter, create timestamp, and build event log activity_log <- data |> dplyr::filter(!!run_col_sym == run_id) |> dplyr::mutate(timestamp_dt = simulation_start + lubridate::dminutes(!!time_col_sym)) |> bupaR::eventlog(case_id = case_id,activity_id = activity_id,activity_instance_id = activity_instance_id,lifecycle_id = lifecycle_id,timestamp ="timestamp_dt",resource_id = resource_id )return(activity_log)}
# Example usage:activity_log <-create_activity_log("resources/complex_event_log_bupar_log.csv")
Rows: 163533 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): pathway, event, event_type, resource_id, lifecycle_id
dbl (4): entity_id, time, run, activity_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: There was 1 warning in `summarize()`.
ℹ In argument: `label = do.call(...)`.
ℹ In group 15: `ACTIVITY_CLASSIFIER_ = NA` and `from_id = NA`.
Caused by warning in `type()`:
! no non-missing arguments to max; returning -Inf
Warning: There were 2 warnings in `summarize()`.
The first warning was:
ℹ In argument: `value = do.call(...)`.
ℹ In group 1: `ACTIVITY_CLASSIFIER_ = "ARTIFICIAL_END"`, `next_act = NA`,
`from_id = 1`, `to_id = NA`.
Caused by warning in `type()`:
! no non-missing arguments to max; returning -Inf
ℹ Run `dplyr::last_dplyr_warnings()` to see the 1 remaining warning.
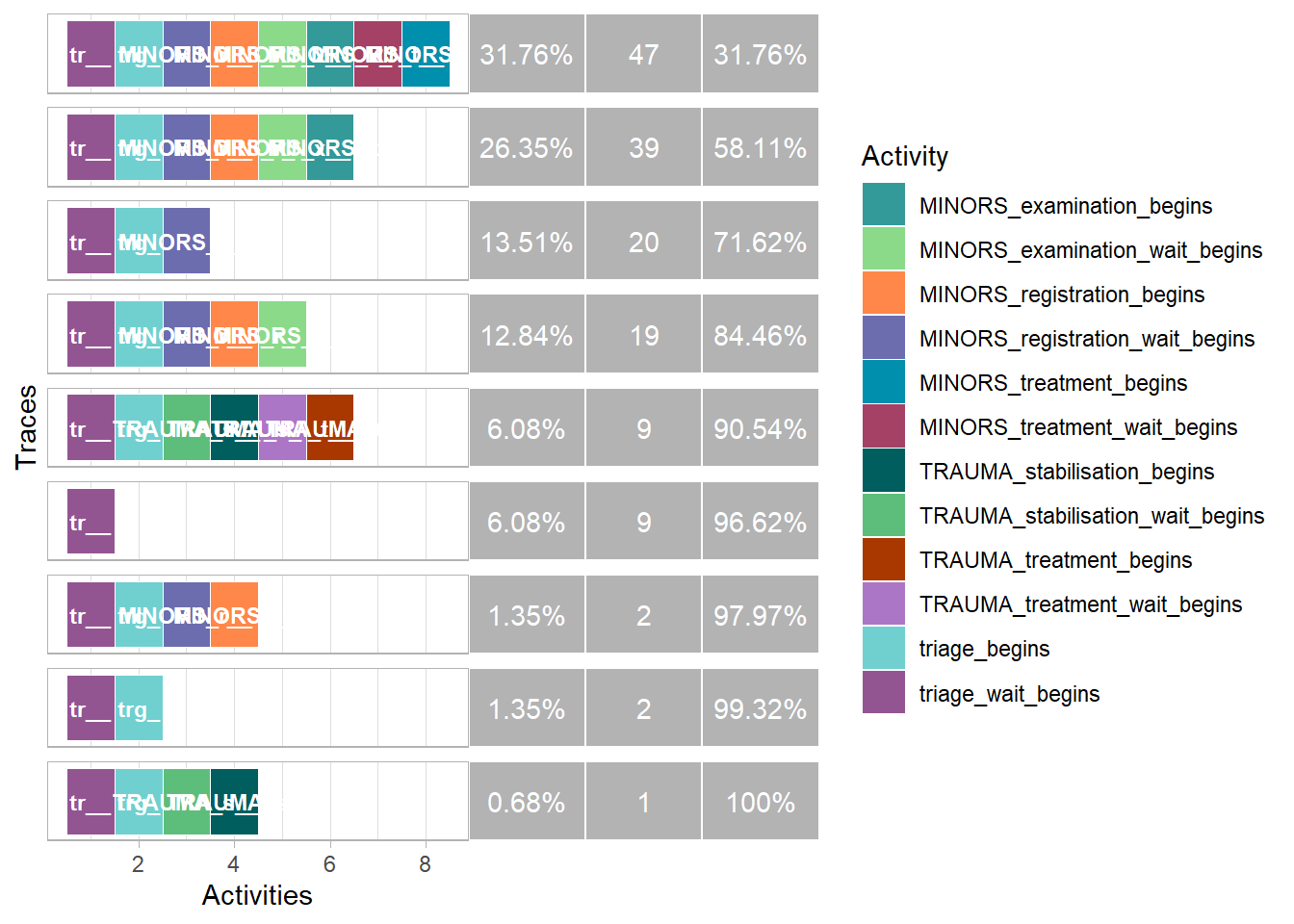
31.2.3.3 Common Routes
activity_log %>%trace_explorer(n_traces =10)
Warning: Fewer traces (9) found than specified `n_traces` (10).
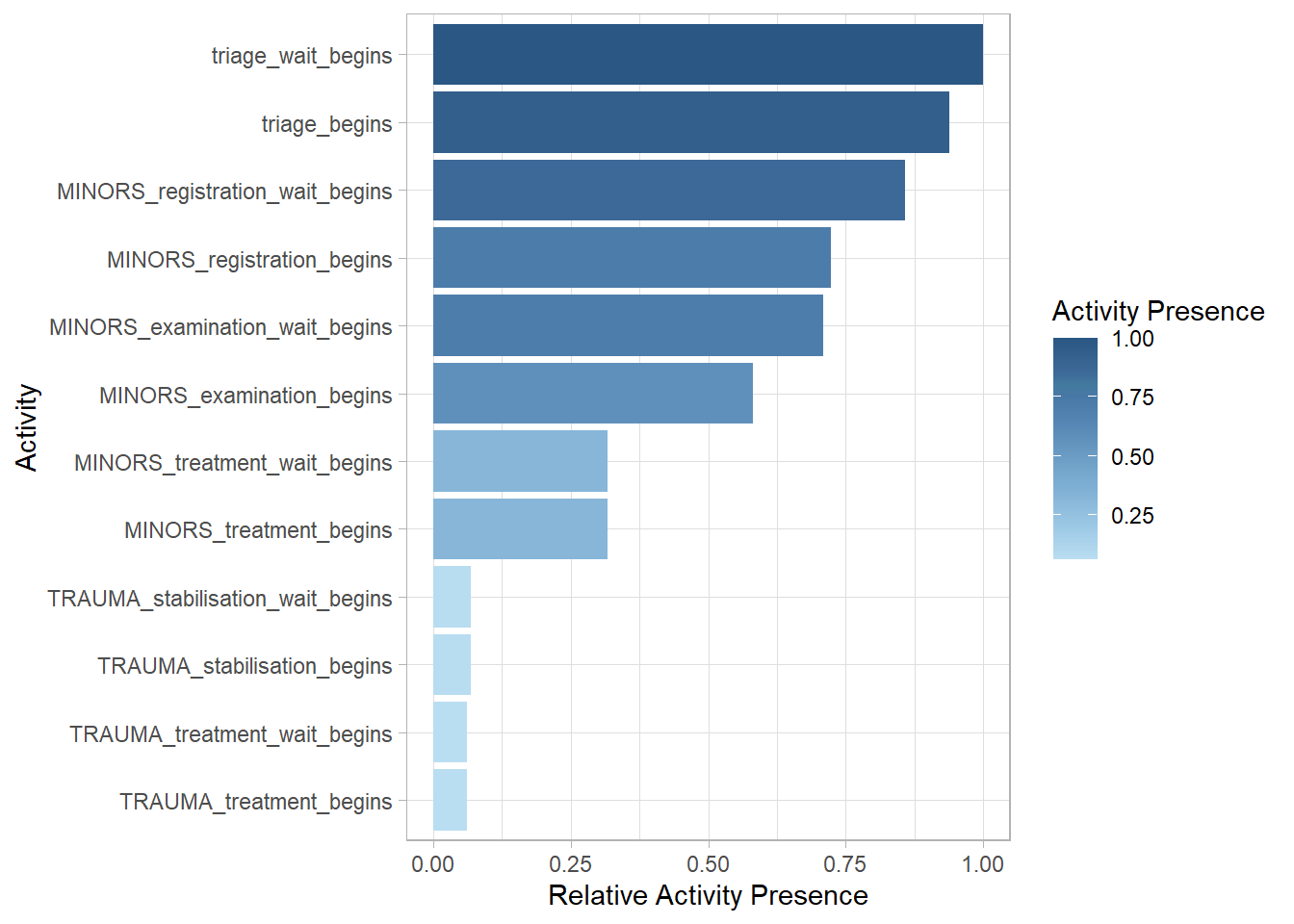
31.2.3.4 Activity Presence
activity_log %>%activity_presence() %>%plot()
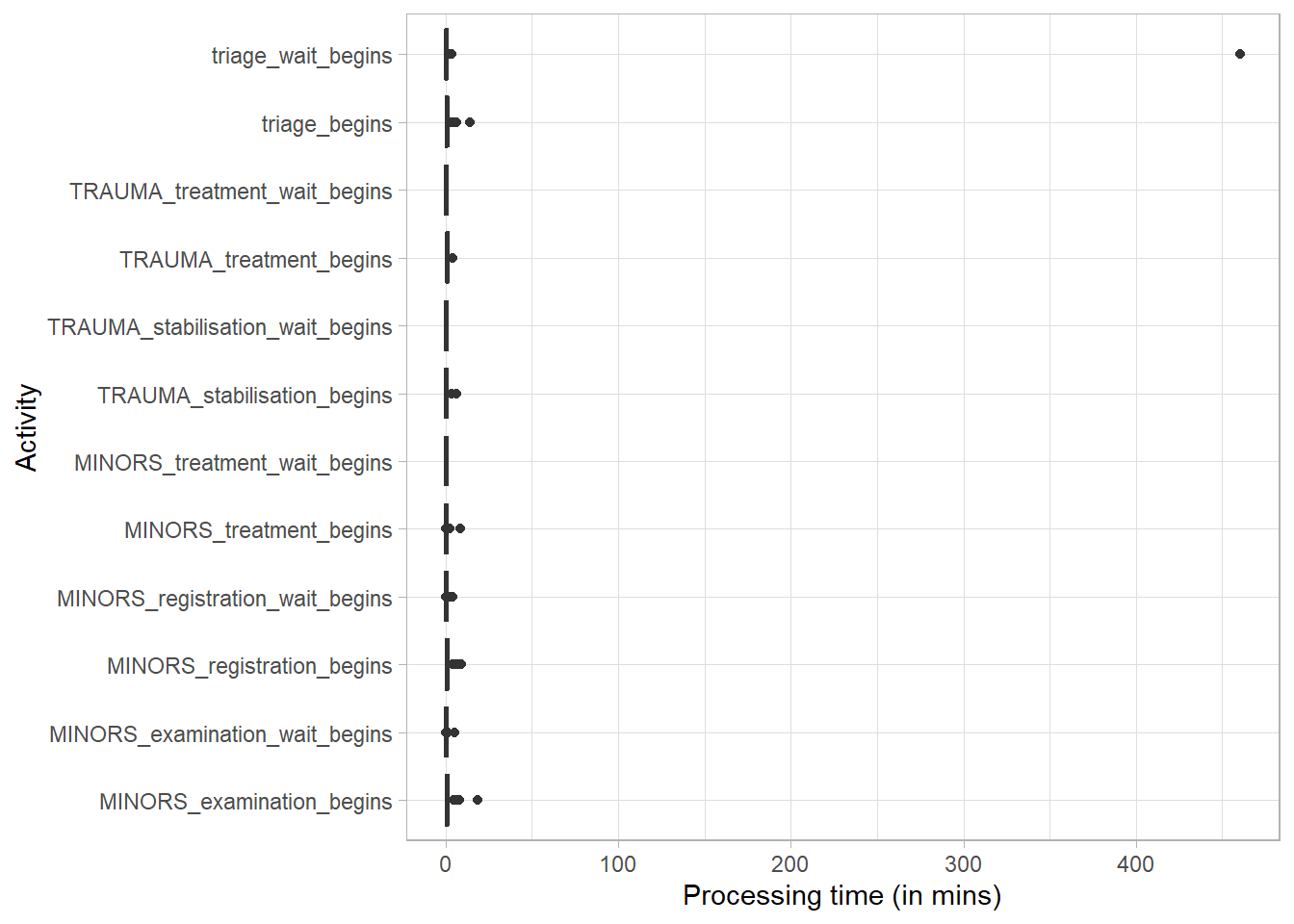
31.2.3.5 Processing Time
activity_log %>%processing_time("resource-activity", units ="mins") %>%plot()
activity_log %>%processing_time("activity", units ="mins") %>%plot()
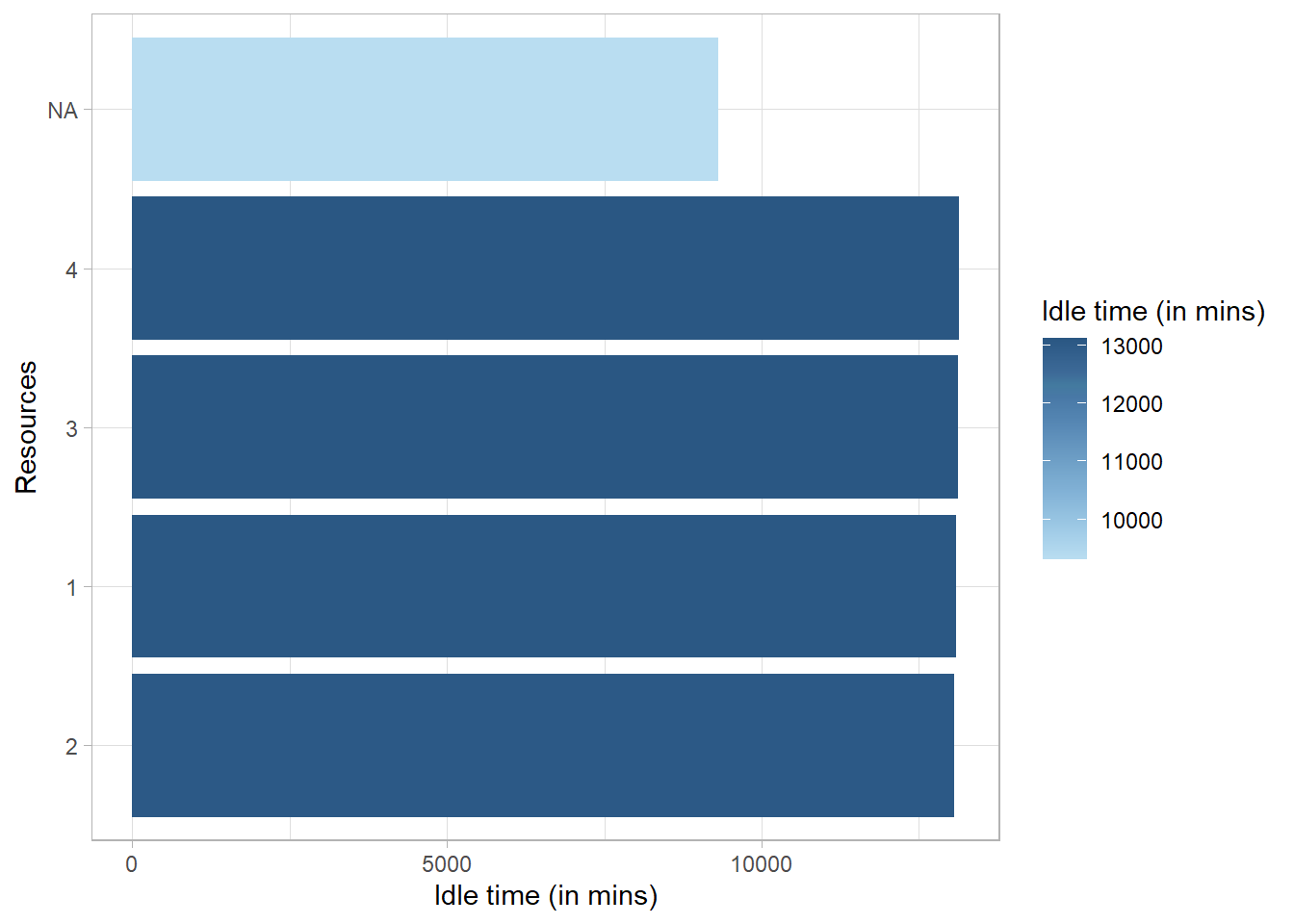
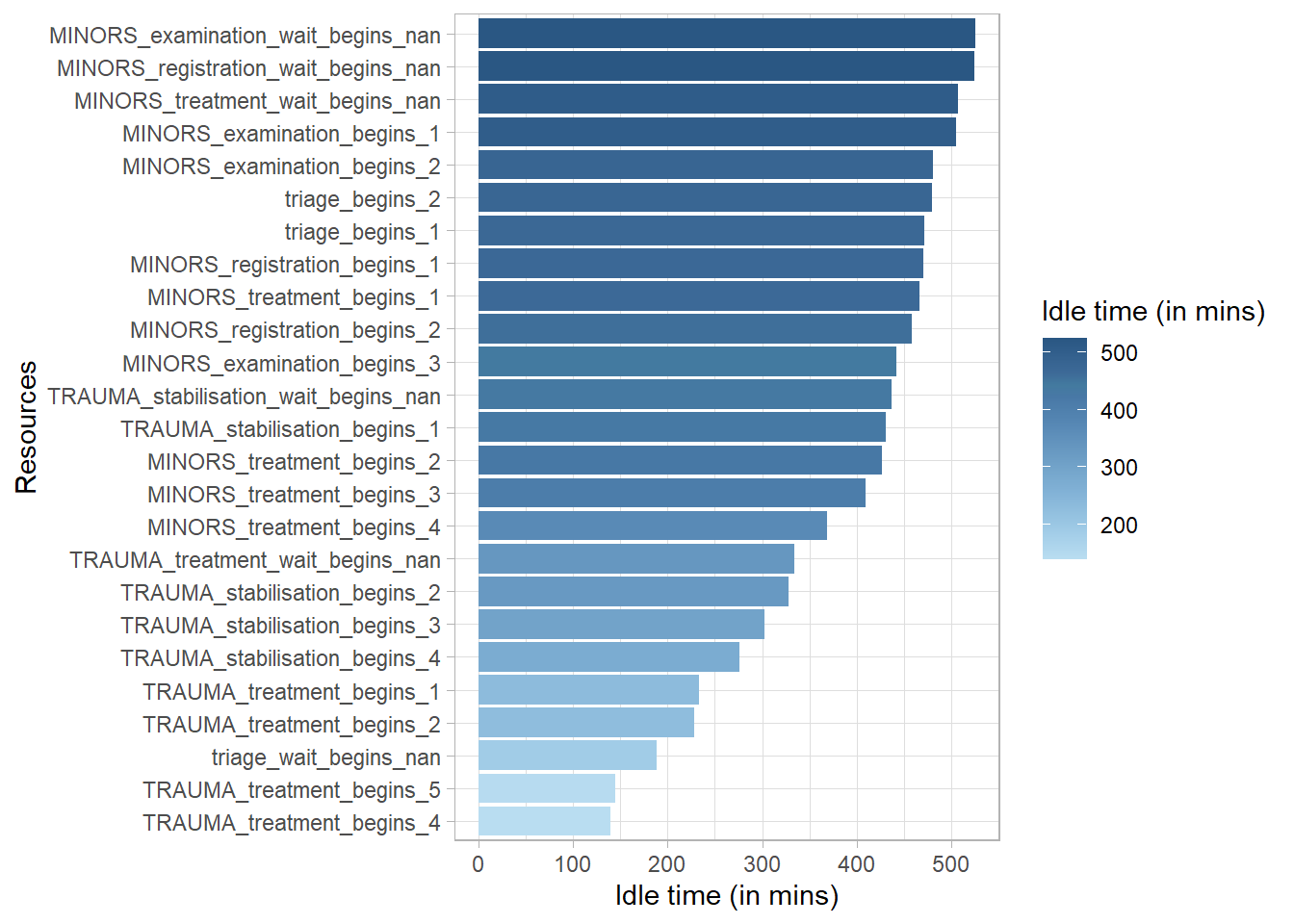
31.2.3.6 Idle Time
activity_log %>%idle_time("resource", units ="mins") %>%plot()